
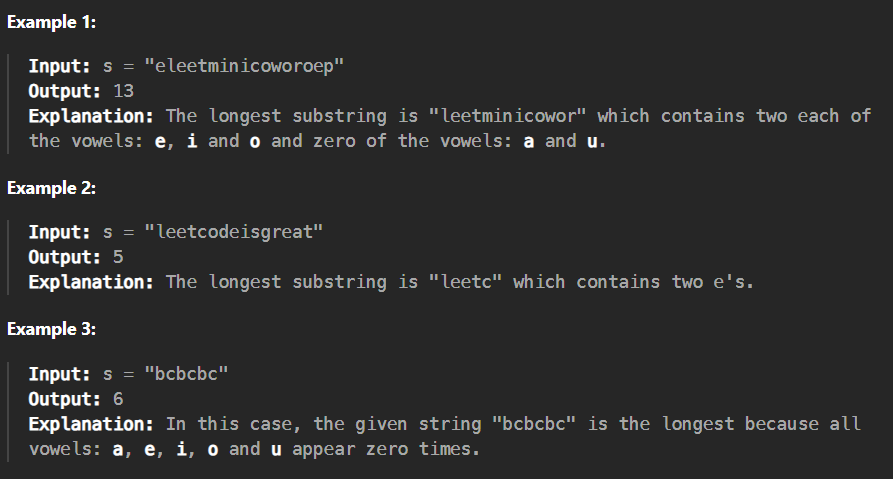
题目概述
Given the string s, return the size of the longest substring containing each vowel an even number of times. That is, ‘a’, ‘e’, ‘i’, ‘o’, and ‘u’ must appear an even number of times.
Constraints:
1 <= s.length <= 5 * 10 ^ 5scontains only lowercase English letters.
解法:位掩码 + 前缀和 + 哈希表
不考虑运行效率的情况下,最朴素的做法是遍历每一个子字符串并统计其中各个元音字母的个数,如果均为偶数则判断这个子字符串的长度是否为最长。在此基础上可以对两个部分进行优化:
- 统计字母频度的方式
- 遍历子字符串的过程
首先是统计字母频度的方式。事实上,统计每个元音字母的具体出现次数是非必要的,因为这个问题只要求奇偶性,我们可以采用另一种更具效率的方式:位掩码(Bitmask)。具体的思路是用一个二进制的0和1表示某一个元音字母出现次数的奇偶性,例如出现偶数次为0,出现奇数次则为1。一个二进制数的不同位代表对应的字母,例如个位对应u,十位对应o,依此类推。
然后是遍历子字符串的过程。利用上述方法可以获取原字符串s到任意索引i为止的各个元音字母出现次数的位掩码。例如s = "leetcode"时:
1
2
3
4
5
6
7
8
i = 0, mask = 00000 (偶数次为0,奇数次为1,从左到右的五位分别对应aeiou)
i = 1, mask = 01000
i = 2, mask = 00000
i = 3, mask = 00000
i = 4, mask = 00000
i = 5, mask = 00010
i = 6, mask = 00010
i = 7, mask = 01010
如果想得到中间某一片段内的情况,例如"etc",对应的是索引2至4的内容,那么应该用i = 4的位掩码与i = 1的位掩码作异或运算,01000 ^ 00000 = 01000。使用异或运算的原因是根据奇偶性运算性质,相同的奇偶性作加减法运算时得到偶数,反之得到奇数。对应到二进制数中也就是希望数字相同时运算得到0,数字不同时运算得到1,正好是异或运算得到的结果。
这时考虑题目中的要求是元音字母出现次数均为偶数,也就是说需要考虑所有掩码为00000的片段的长度,从中找出最长的那一个。那么问题来了:掩码为00000的片段中,它的两个端点的掩码需要满足什么条件? 答案是:两个端点的掩码必须相同。 至于原因,各位读者可以自己思考一下,其实在先前的解说中已经提到了。
于是,我们就有了一个很巧妙的解法。我们只需要建立一个哈希表,其中的key为掩码值,对应的value存储该掩码值的两个端点索引。因为只需要求最长片段,所以依照遍历的顺序对右端点进行更新即可。最后计算各个掩码值下的最长片段,再比较出其中最长的那一个。
代码实现
初始化
- 建立元音字母与掩码位数的对应关系
1 2
bit_map = {"a": 1, "e": 2, "i": 4, "o": 8, "u": 16} mask = 0
- 建立存储掩码的哈希表,和记录最终答案的变量
1 2 3 4
from collections import defaultdict mask_map = defaultdict(list) mask_map[0] = -1 # 空字符串作为特例,提前存储左端点为-1,便于后续的子字符串长度计算 ans = 0
计算掩码的前缀和
- 遍历字符串,计算掩码的前缀和,并对哈希表进行更新
1 2 3 4 5 6 7 8 9 10 11
for i, c in enumerate(s): # 当前字母为元音时,更新掩码的前缀和 if c in bit_map: mask ^= bit_map[c] # 更新对应掩码的片段端点 if len(mask_map[mask]) < 2: mask_map[mask].append(i) else: mask_map[mask][-1] = i
计算最终结果
- 计算满足条件的最长子字符串的长度
1 2 3 4
for mask_indexs in mask_map.values(): ans = max(ans, mask_indexs[-1] - mask_indexs[0]) return ans
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Solution:
def findTheLongestSubstring(self, s: str) -> int:
bit_map = {"a": 1, "e": 2, "i": 4, "o": 8, "u": 16}
mask = 0
mask_map = defaultdict(list)
mask_map[0] = [-1]
ans = 0
for i, c in enumerate(s):
if c in bit_map:
mask ^= bit_map[c]
if len(mask_map[mask]) < 2:
mask_map[mask].append(i)
else:
mask_map[mask][-1] = i
for mask_indexs in mask_map.values():
ans = max(ans, mask_indexs[-1] - mask_indexs[0])
return ans
结果顺利通过。
Time complexity: $O(n)$
Space complexity: $O(1)$
